1. 注意力机制#
基本概念#
| Query (Q) | 表示当前需要查询的信息,可理解为想要获取的信息 |
| Key (K) | 表示输入元素的特征表示,可理解为内容的“主题”,用于与 Query 匹配 |
| Value (V) | 表示输入元素的实际内容,可理解为通过对应 Key 获取的结果。 |
所谓注意力机制,即通过计算 Query 与所有 Key 的相似度(相关性),得到注意力权重(经 Softmax 归一化), 再用这些权重对 Value 进行加权求和,最终输出一个聚焦于关键信息的上下文向量。
自注意力 (Self-Attention)#
自注意力机制是注意力机制的一种形式,其 Query、Key、Value 都来自同一个输入序列。 利用自注意力机制,在处理某个特定位置的输入时,能够考虑到整个序列的所有位置的信息。
设由若干序列(向量) 组成的输入矩阵为 ,得到由若干结果序列 组成的输出矩阵为 。 我们可以推导出自注意力机制的公式:
先从第一个序列处理,计算 Query 与 Key 的相似度,也称为注意力分数,经过归一化后得到注意力权重。
设 , ,上述过程如下图所示:
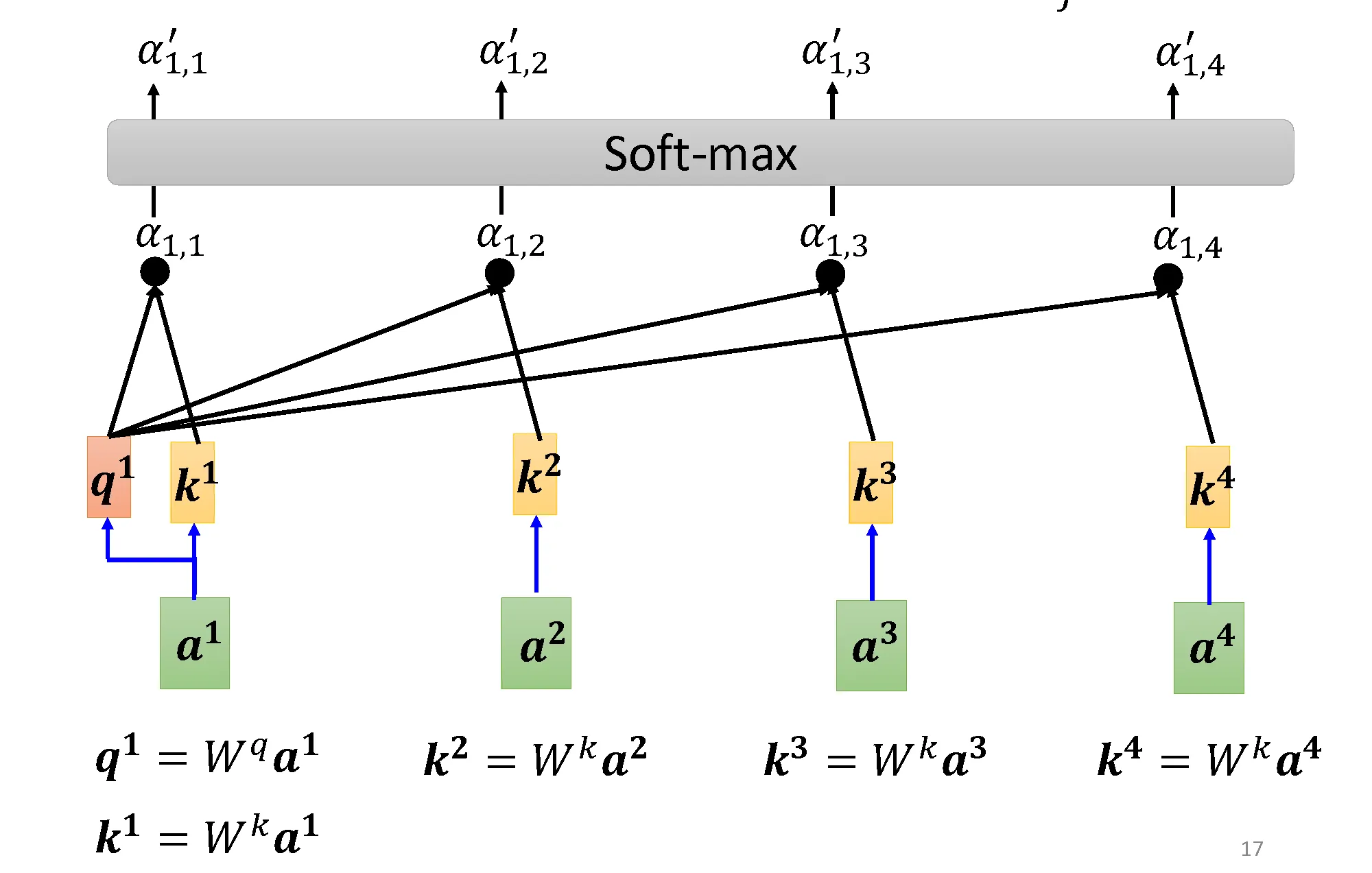
图中的 代表注意力分数, 代表注意力权重。
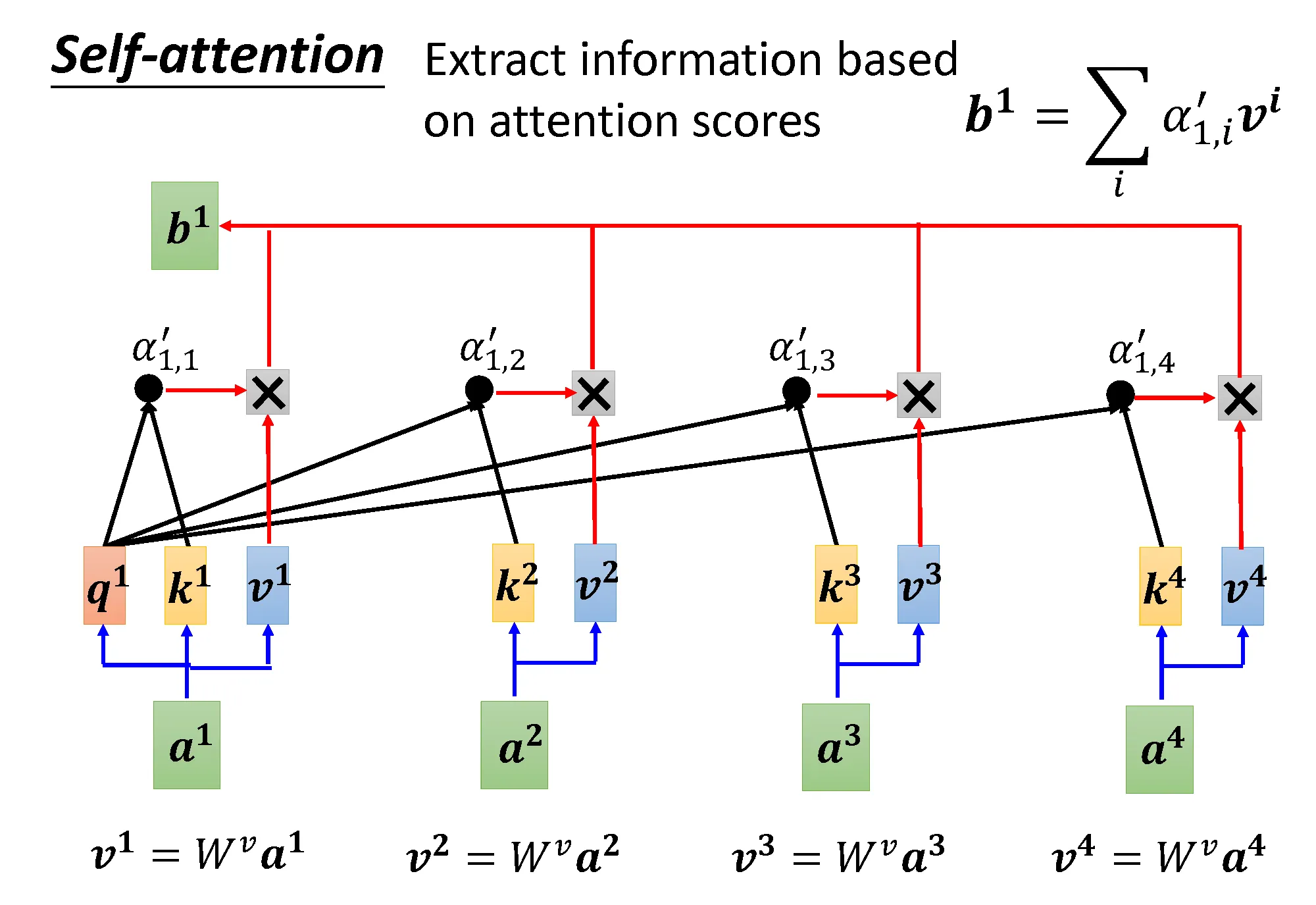
通过注意力权重,对 Value 进行加权平均得到最后结果 ,该过程流程如下图所示:
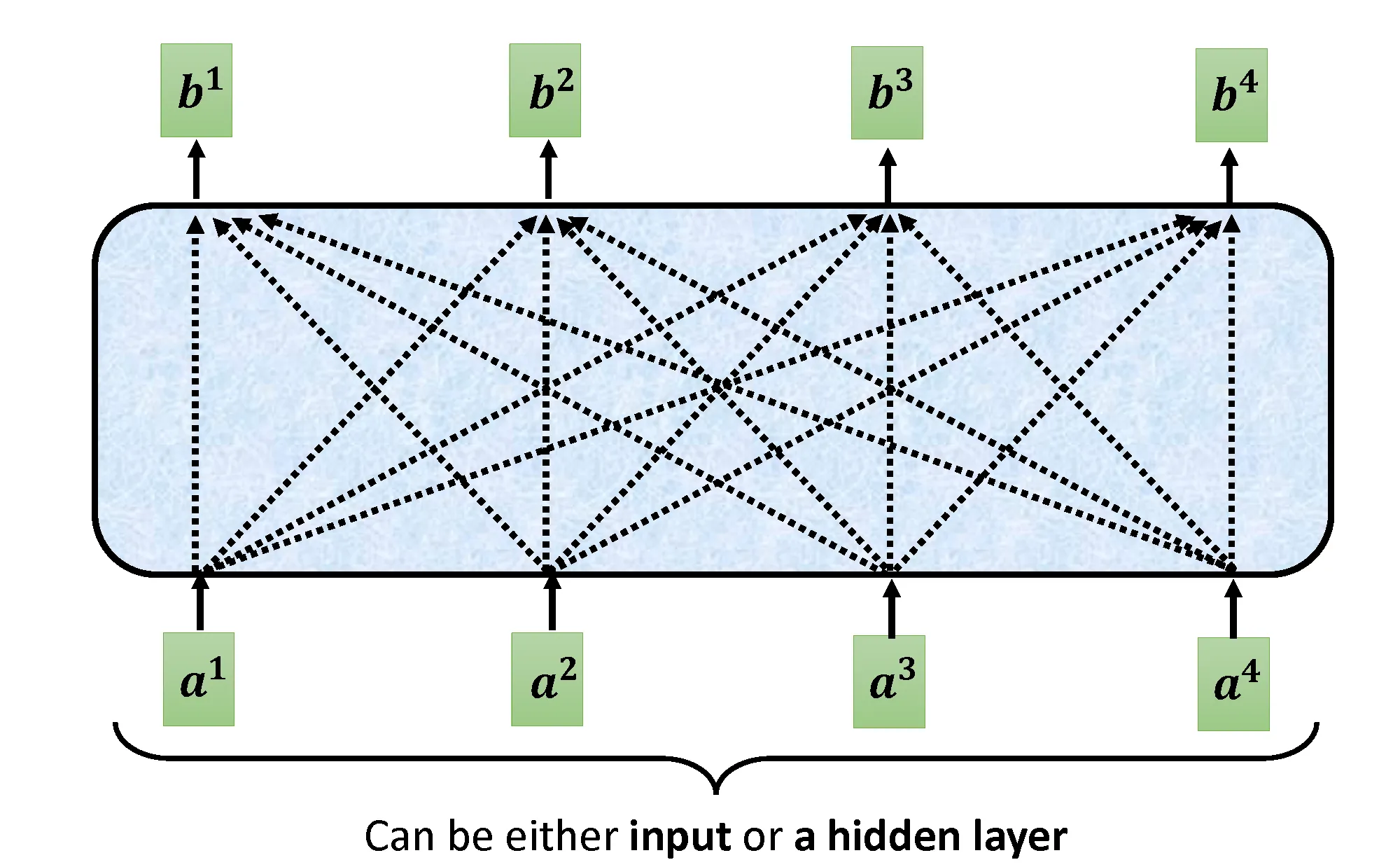
对每一个输入元素都并行进行上述操作得到输出,如下图:
如果我们将这些向量拼起来用对应矩阵表示,上面的过程可以用矩阵乘法表示为:
多头注意力 (Multi-Head Attention)#
当给定相同的Query、Key、Value的集合时,我们希望能够学习出不同的行为。
于是,我们使用多头注意力将输入的特征(Query、Key、Value)通过多个独立的、并行运行的注意力模块(或称为“头”)进行处理。

2. Transformer#
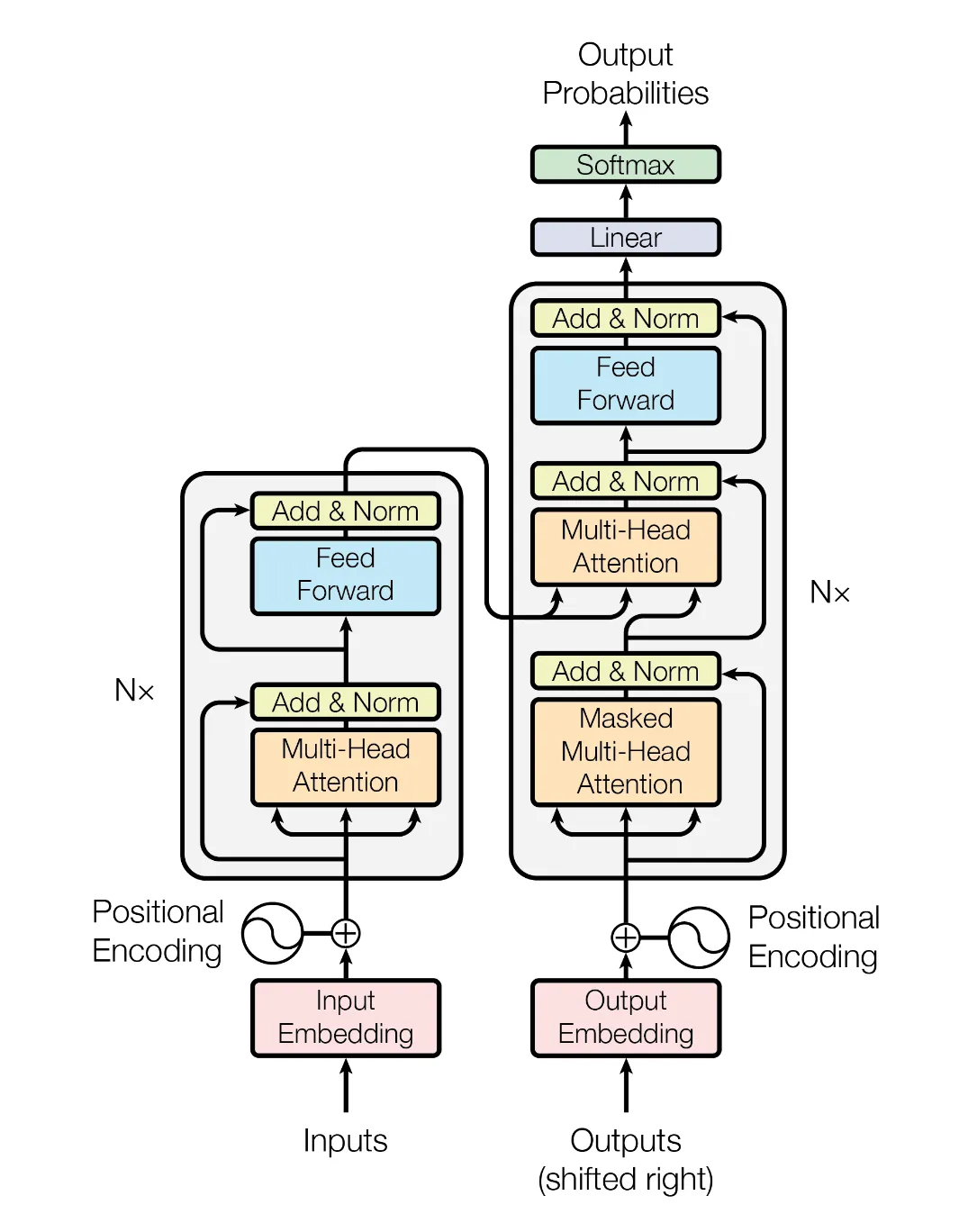
Transformer模型完全基于注意力机制,其整体为编码器-解码器架构。
输入序列和输出序列的嵌入 (embedding) 表示加上位置编码 (positional encoding), 再分别输入到编码器和解码器中。
嵌入层 (Embedding)#
嵌入层是模型处理输入数据的第一步,它的核心作用是将离散的符号转换为计算机可以处理的、富含语义信息的向量。 嵌入层本质上是一个巨大的查找表,也称为嵌入矩阵。
| 特性 | One-Hot 编码 | 嵌入 (Embedding) |
|---|---|---|
| 表示方式 | 每个类别用一个独热向量表示:向量长度 = 类别总数,只有一个位置是 1,其余全是 0 | 每个类别映射到一个低维稠密向量(如50维、128维),向量中的每个值都是 float |
| 示例 | cat → [1, 0, 0] dog → [0, 1, 0] (维度等于全部词汇数量,通过向量映射到词汇表的特定类型) | cat → [0.8, -0.3, 0.5, ..., 0.1] dog → [0.7, -0.2, 0.6, ..., 0.2] (维度固定,向量由模型学习得到) |
位置编码 (Positional Encoding)#
处理一组序列时,RNN 是串行处理序列,而自注意力使用并行计算。 为了获得序列的顺序信息,通过在输入中加入位置编码的方式来注入绝对或相对的位置信息。位置编码可以固定也可通过学习得到。
位置参数使用形状相同的嵌入矩阵 , 对于输入 得到的输出为 。 特别的,有一种基于正弦函数和余弦函数的固定位置编码,对 ,有
编码器 (Encoder)#
编码器是由多个结构相同的层堆叠而成,每个层由两个子层 (多头自注意力和前馈网络) 组成。源序列经过嵌入层,再与位置编码相加,得到的结果作为编码器层的输入。
第一个子层对输入序列使用多头注意力,第二个子层是一个基于位置的前馈网络,对序列中的位置表示使用多层感知机,两个子层周围均适用残差连接,再进行层归一化 (Layer Normalization)。
解码器 (Decoder)#
解码器同样是由多个结构相同的层堆叠而成,每个层由三个子层组成。目标序列经过嵌入层,再与位置编码相加,得到的结果作为解码器层的输入。
解码器的第一、三个子层分别与编码器的第一、二个子层结构相同。而其中间层在编码器输出和解码器第一个子层的输出上进行多头注意力,然后在子层使用残差连接,再进行层归一化。
自回归 (Autoregressive)#
Transformer 用于序列生成任务,在生成当前词的时在只能依赖于之前已经生成的词,而不能看到未来信息。因此,在其编码器的自注意力层中,使用了**掩码(Mask)**确保每个位置只能关注到自己以及之前的token。